
HOME · Twitter · Flickr · LinkedIn · publications · @ Ars Technica · Running IPv6 (Apress, 2005) · BGP (O'Reilly, 2002) · BGPexpert.com · presentations · iljitsch@muada.com
![]() English version of this article
English version of this article
Posted 2014-07-17
Een deel van de lezers van ISP Today zal wel eens naar een RIPE meeting geweest zijn, waar medewerkers van ISPs en internet-experts van verschillend pluimage bij elkaar komen om het wel en wee van het internet te bespreken. In Amerika vervullen de bijeenkomsten van de North American Network Operators Group (NANOG) een soortgelijke functie. Een bekend gezicht bij zowel RIPE als NANOG is Geoff Huston, Chief Scientist van APNIC, de Aziatisch/Australische tegenhanger van RIPE.
Op de NANOG-meeting in februari presenteerde Geoff "BGP in 2013", een overzicht van hoe het Border Gateway Protocol ervoor stond vorig jaar. BGP is het routingprotocol dat de routers van verschillende ISPs met elkaar spreken zodat de pakketten van een klant van ISP A zich een weg weten te vinden naar een klant van ISP B. Iedere ISP "adverteert" dus zijn IP-adresreeksen in BGP, wat een totaal van ongeveer een half miljoen adresblokken (prefixen) oplevert die de BGP-routers van verschillende ISPs met elkaar uitwisselen.
Toen ik in 1995 met BGP begon was dit nog 30 duizend. De groei van de BGP-tabel is al lang een punt van zorg. In 2006 organiseerde de Internet Architecture Board, een soort technische raad van toezicht van de IETF, een bijeenkomst over dit onderwerp in Amsterdam. Geoff Huston ziet echter geen problemen op de korte/middellange termijn: "Niks in BGP ziet eruit alsof het aan het smelten is."
Opmerkelijk genoeg was de groei in het aantal BGP-prefixen in 2013 met 11% niet noemenswaardig lager dan in voorgaande jaren, ondanks het feit dat APNIC en het RIPE NCC al in respectievelijk 2011 en 2012 door hun normale voorraden IPv4-adressen heen waren en ISPs alleen nog één laatste blok van 1024 adressen konden krijgen. Maar als je kijkt naar het aantal losse adressen dat in BGP geadverteerd wordt is de groei wel minder. De adresblokken zijn dus kleiner geworden met het opraken van de IPv4.
Irritant genoeg bestaat de helft van de half miljoen prefixen die BGP-routers in hun tabellen moeten bewaren uit kleine adresblokken (lange prefixen) die vallen binnen een groter blok (korte prefix) die ook in de BGP-tabel aanwezig is. Een beetje alsof er onder het bord "Noord-Holland" ook nog bordjes "Amsterdam" en "Alkmaar" zitten. Nogal overbodig, maar het neemt wel schaarse ruimte in. Vervolgens blijkt dat van de BGP updates, de pakketten die BGP-routers elkaar sturen als er wat verandert, 80% gaat over die gedeaggregeerde prefixen!
Maar de grafiek uit Geoff Huston's presentatie die me echt versteld deed staan is deze, die de Wet van Moore laat zien versus de groei in BGP:
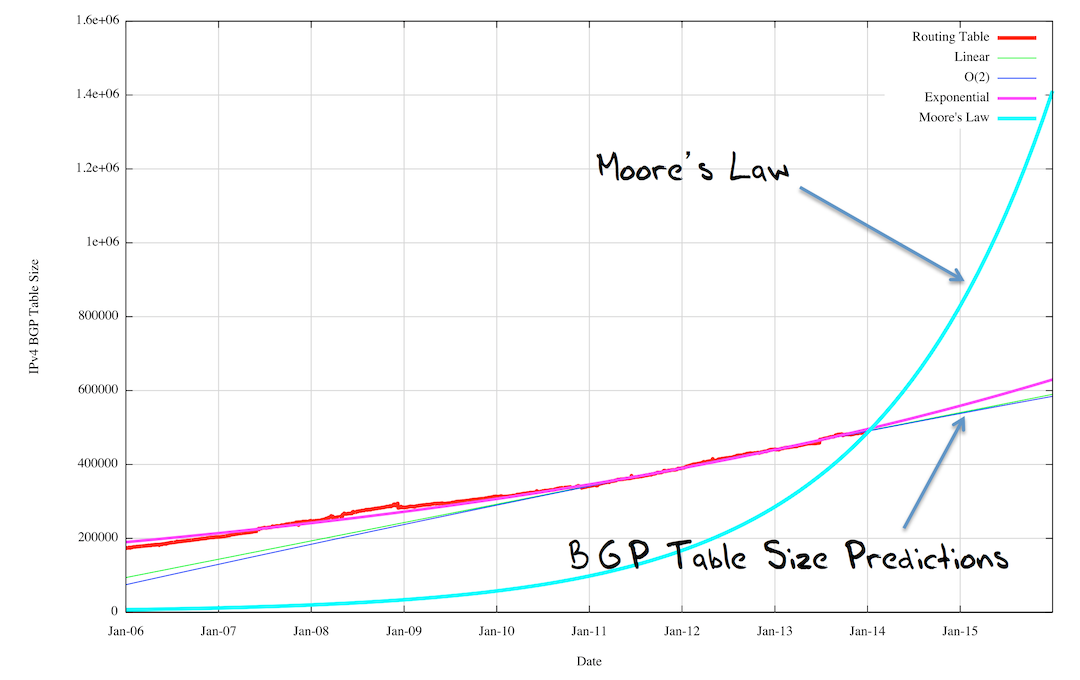
Gordon Moore, één van de oprichters van Intel, stelde in 1965 dat het aantal transistors in een chip iedere twee jaar zou verdubbelen. Met twee keer zo veel transistors kan je in principe twee keer zoveel werk in dezelfde tijd doen, of hetzelfde werk twee keer zo snel.
Zolang de BGP-tabel minder snel groeit dan de chips sneller worden zitten we dus goed, zou je zeggen. Maar die gedachte gaat uit van de aanname dat twee keer zoveel prefixen in de BGP-tabel twee keer zoveel werk betekent. Voor de CPU die het BGP-protocol runt is dat wel (ongeveer) waar, maar dit geldt niet voor de hardware die voor het daadwerkelijk doorsturen van IP-pakketten zorgt. Dit is vaak een ASIC (application specific integrated circuit, een chip gemaakt voor een specifieke taak) die voor ieder pakketje de hele tabel door moet om te vinden binnen welke prefix het bestemmingsadres van het pakket valt. Het doorzoeken van een twee keer zo grote tabel kost niet zo heel veel extra tijd, maar die grotere tabel neem wel twee keer zoveel speciaal, snel geheugen in beslag. Hierin wordt de zogenaamde "forwarding information base" (FIB) opgeslagen.
Het probleem is echter dat als de router sneller wordt en meer pakketten per seconde moet routeren/forwarden, het FIB-geheugen ook sneller moet worden. Groter en sneller is natuurlijk geen goede (of goedkope) combinatie. Het lijkt er niet op dat we op korte termijn in de problemen zullen raken door deze ontwikkelingen, maar het zou toch wel erg prettig zijn om van al die onnodig gedeaggregeerde prefixen af te komen, om te voorkomen dat routers onnodig snel veel duurder worden.
Tot zover IPv4. Hoe zit het met IPv6? Dat groeit, iets sneller dan IPv4, maar niet overdreven hard. In het huidige tempo haalt IPv6 IPv4 in in het jaar 2030. Wel neemt de deaggregatie in IPv6 toe richting de 50% waarop IPv4 al een tijd zit.
Geoff's presentatie is hier te vinden, een video van zijn verhaal op de NANOG website, of lees Addressing 2013 en vooral BGP in 2013 - The Churn Report op zijn blog, waar hij maandelijks een gedegen verhaal plaatst.
Dit artikel is ook geplaatst op ISP Today.